
En nuestro universo, todo lo que podemos tocar, ver, oler o sentir es sólo el 5% de todo lo que existe. La materia a la que estamos acostumbrados a tratar y ver es bastante rara en el universo.
Si sólo conocemos un 5%, ¿qué ocurre con el resto? Las evidencias hacen sospechar que un 27% de la masa y energía del universo está formado por la denominada materia oscura. Aunque hoy día la materia oscura sigue siendo un auténtico misterio, ¿qué conocemos sobre la materia oscura? ¿Para qué sirve?
La materia oscura
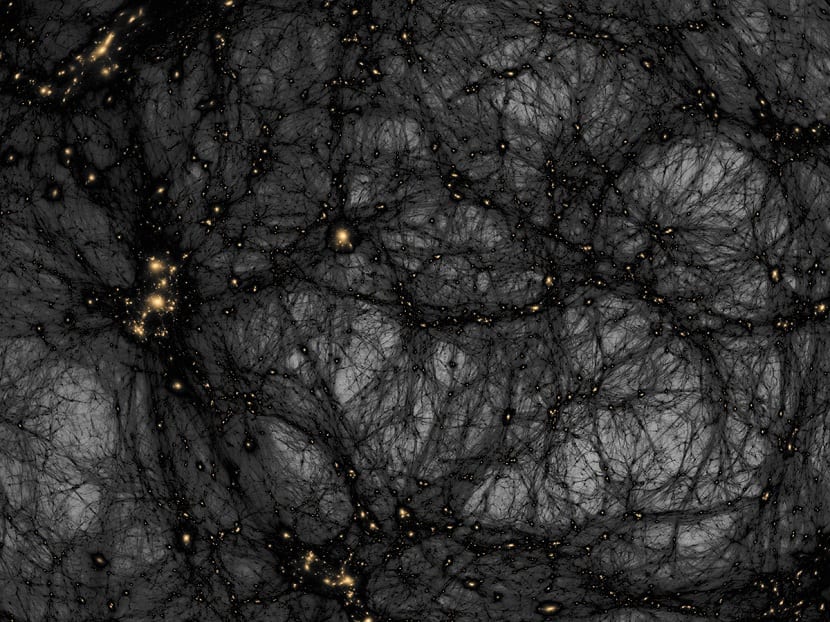
Nuestro universo está compuesto por materia y energía. Estamos acostumbrados a tratar con materia a todas horas del día. Un ordenador, nuestro smartphone, una mesa, etc. Están compuesto de materia ordinaria. Sin embargo, nuestro universo no está compuesto en su totalidad de materia ordinaria, sino de materia oscura.
Esta materia oscura no puede verse a simple vista, pero es la que le otorga la dinámica a todo el universo. La materia oscura no puede ser vista porque se encuentra en el espacio más profundo y está muy fría. Para observar los cuerpos celestes desde este pequeño planeta lo que se hace es detectar radiaciones, que viajan a través del espacio. Esas radiaciones permiten interpretar la presencia de la materia oscura.
La materia oscura no emite una radiación suficiente para que se pueda ver, pero está ahí y se analiza mediante instrumentos y análisis estadísticos, para ver cómo funciona. La materia oscura está tan fría y es tan negra que no emite nada, por tanto, no se puede ver.
Debido a que no se puede analizar, no se sabe de qué está compuesta. Se deduce que puede estar formada de neutrinos, partículas WIMP, nubes de gas no luminoso o incluso estrellas enanas.
¿Cómo se sabe que la materia oscura está ahí?

Esa pregunta es bastante interesante, puesto que si no se puede tocar ni detectar, es imposible de ver. Se podría decir que la materia oscura forma parte de nuestra imaginación y fantasía, pero la ciencia se basa en evidencias.
Si bien es cierto que la existencia d la materia oscura es solo una hipótesis, es decir, todavía no es un hecho contrastado y demostrado, existen numerosas evidencias que muestran inequívocamente que está ahí.
Se descubrió en 1933, cuando F. Zwicky propuso su existencia como respuesta a un efecto que no podía explicar: la velocidad a la que se mueven las galaxias no concordaba con la que se cabía esperar tras los estudios y cálculos realizados. Esto ya se había detectado mucho antes por varios investigadores.
Tras algunas observaciones posteriores, se descubrió la existencia de una masa que alteraba el espacio y la interacción gravitatoria de los cuerpos celestes, pero que no se puede ver. Sin embargo, debe estar ahí. Para observar los efectos de la materia oscura, se debe mirar cuerpos celestes lejanos, como otras galaxias.
¿Para qué sirve la materia oscura?

Si la materia oscura no se puede ver, ni tocar, ni detectar de ninguna forma, ¿para qué queremos saber sobre la materia oscura? Básicamente, los científicos intentan buscar explicaciones sobre la dinámica del universo. El movimiento de los cuerpos celestes, la inercia, el big bang… todo tiene su explicación si introducimos la presencia de la materia oscura.
La materia oscura sólo sirve realmente para conocer al universo de una forma más íntima. Es una consideración, un ente, que nos permite entender mejor cómo funciona la materia que conocemos, así como revelar la que no conocemos. Estudiando unas partículas cuya interacción es tan débil nos permite descubrir aspectos que nunca hubiéramos imaginado de nuestro universo. Esto convierte a la materia oscura en una herramienta, más que una hipótesis, invaluable. Y eso que ni si quiera podemos verla.
Sea lo que sea la materia oscura, está claro que es importante dado que la mayoría del universo que conocemos está formada por ella. Además, podría darnos muchas soluciones acerca del funcionamiento de nuestro universo.